Cuda 프로세서에 대해 알아보자
이번 글은 이 분의 글을 참고했다.
CUDA 프로세서가 어떤 구조로 이뤄졌는지 물리적인 구조와 논리적인 구조에 대해 살펴보겠다.

위 그림은 CUDA Processor 의 구조이다. 큰 네모 15개 가 보이는데 이를 CUDA-Multi-Processor라고 부른다. CUDA-Multi-Processor는 CUDA가 작업을 처리하는 단위이다. kernel 함수를 콜하면 각 Multi-Processor에 작업이 분할 된다. 아래는 이를 더 상세히 본 그림이다.
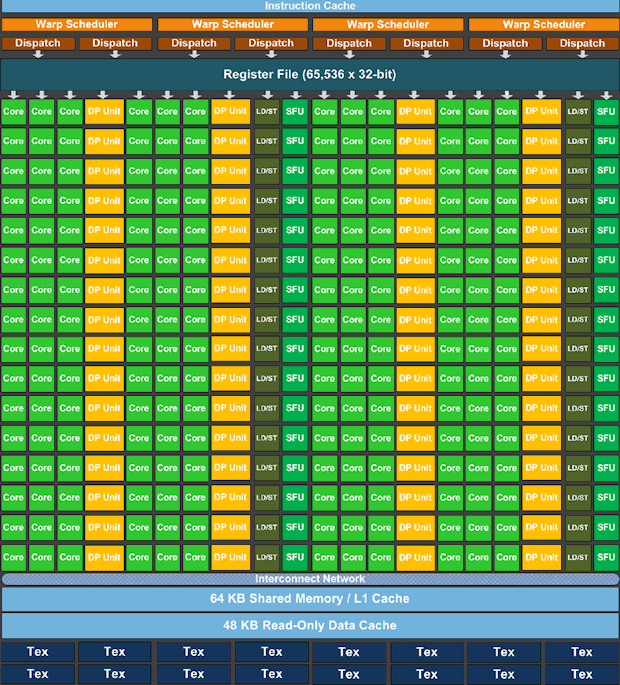
Core, DP Unit, SFU 는 모두 연산을 수행하는 장치이다. Core는 Single Point 연산을 수행한다. CUDA가 single floating 연산에 강한 이유는 Core 갯수가 많기 때문이다.
Shared Memory(L1 Cache) 와 Read-Only Data Cache 는 메모리인데 커널 내에서 공유되며 Shared Memory 는 읽기/쓰기 버퍼로 활용된다.
CUDA 의 논리적 구조는 물리적 구조와 상관관계를 이해하며 살펴보도록 하자.
| 물리적 구조 | 논리적 구조 |
| CUDA Processor | CUDA Kernel/Grid |
| CUDA Multi-Processor | 복수의 CUDA Block |
| CUDA Core | CUDA Thread |
CUDA Kernel 콜하면 작업을 CUDA Multi-Processor로 나눈다. 이때 작업은 CUDA Block 단위로 나뉜다. 하나의 Multi-Processor는 복수의 CUDA Block 을 처리한다. 각각의 CUDA Core가 CUDA Thread를 처리한다.
중요한 점은 CUDA의 하드웨어가 계층적으로 구성이 되어있으며, CUDA 프로그래밍도 이 계층의 영향을 받는다는 것이다.
CUDA Thread Index
CUDA 에는 CUDA Thread Index를 위한 키워드가 존재한다.
| 키워드 | 설명 | 차원 |
| gridDim | Kernel의 block 수 | x, y |
| blockIdx | Block Index | x, y |
| blockDim | block 크기 | x,y,z |
| threadIdx | Thread Index | x,y,z |
1920 x 1080 크기의 데이터를 16 x 16 크기의 CUDA Block 으로 나눈다면 CUDA Block 은 총 몇 개가 필요할까. CUDA Block은 쪼개질 수 없다. 그렇다면 먼저 가로에 120개의 block이 필요할 것이다. 세로는 67.5개가 필요한데 타일을 나눌 수 없으므로 모두 커버하려면 68개가 필요하다. 따라서 필요한 총 block 수는 120*68 개 이다.
이를 CUDA 의 키워드로 나타내면 다음과 같다. GridDim.x : 120, GridDim.y : 68, BlockDim.x : 16, BlockDim.y : 16
BlockDim을 16으로 정해준 것 처럼 GridDim 도 정해주어 적절한 수의 Block을 생성하도록 도와주어야 한다. 이를 코드로 공식화하면 다음과 같다.
GridDim.x = (Data_width + blockDim.x -1) / blockDim.x
GirdDim.y = (Data_height + blockDim.y -1) / blockDim.y그냥 올림해도 된다.
CUDA thread 자신의 Index를 알고 있는데 이는 block 내 상대적인 위치이다. 따라서 절대적인 위치를 알기 위해서 다음과 같이 생각할 필요가 있다. block index를 알고 있고 blockDim 을 알고 있으므로 threadIndex.x의 절대값을 구하면 blockDim.xblockIdx.x + threadIndex.x y좌표도 마찬가지로 blockDim.yblockIdx.y + threadIndex.y 이다.
global, __device 의 차이에 대해 알아보자
CUDA 프로그래밍 소스를 보면 함수 앞에 global, device 와 같은 키워드가 붙은 것을 볼 수 있다. global 이 붙은 함수는 호스트(CPU)에서 호출할 수 있고 디바이스(GPU)에서 호출 할 수 없다. 디바이스에서 실행된다. device 이 붙은 함수는 호스트(CPU)에서 호출할 수 없고 디바이스(GPU)에서 호출 할 수 있다. 디바이스에서 실행된다.
global 함수에서는 device 함수를 호출 할 수 있다. global 함수는 다른 말로 커널 함수라고 한다. 지시어가 붙지 않은 모든 함수는 host 지시어가 생략된 것이다.