Cuda Programming 기초를 알아보자
CUDA(Computed Unified Device Architecture) 는 NVIDIA에서 개발한 GPU 개발툴이다. CUDA 이외에 OpenCL 이라는 개발 툴도 있다. OpenCL 은 다양한 기종에서 수행 가능한 GPU 병렬처리 개발환경을 제공한다. Nvidia 는 CUDA 를 사용하고 Intel, AMD 등의 GPU 에서는 OpenCL 로 병렬처리를 수행하는 일이 많다고 한다. OpenCL은 병렬처리 한 결과를 생성하고 기존 프로젝트에서 import 해서 사용해야 한다. 이에 비해 CUDA 는 C / C++ 로 코딩하고 프로젝트 내에서 함께 컴파일하여 사용할 수 있다.
우리는 Nvidia CUDA 를 이용한 병렬처리 방법을 알아볼 것이다.
우선 알맞은 버전의 CUDA를 설치한다. CUDA 설치 방법은 쉬우므로 생략하기로 한다.
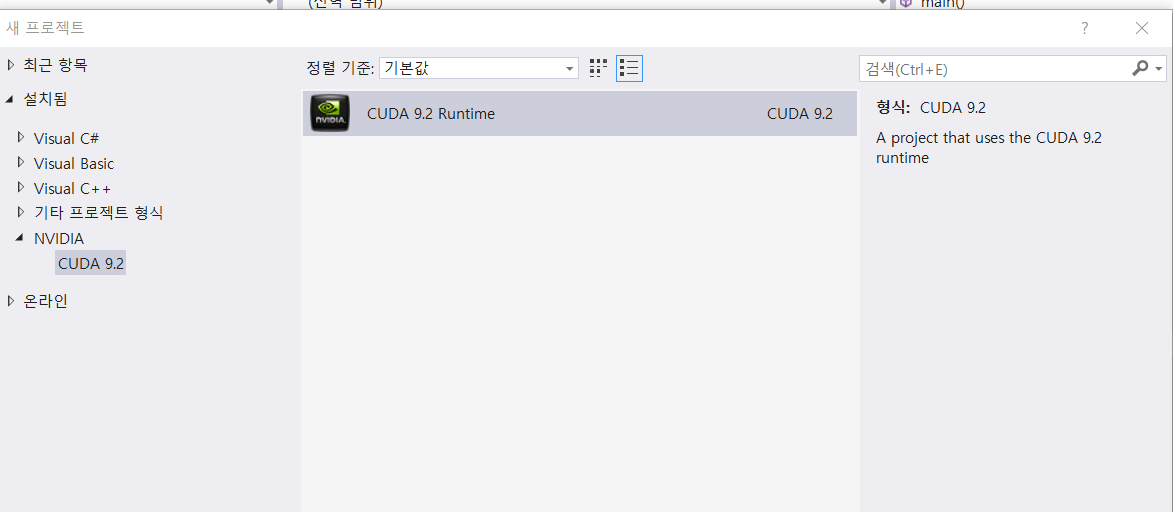 Nvidia 항목이 생긴것을 확인하고 클릭하여 프로젝트를 생성한다.
Nvidia 항목이 생긴것을 확인하고 클릭하여 프로젝트를 생성한다.
생성하면 kernel.cu 라는 소스가 자동으로 생성된 것을 확인할 수 있다. CUDA 소스는 확장자가 cu 이다.
예제 소스 kernel.cu 를 보면서 어떤 방식으로 돌아가는지 간단히 이해해보자. 메인 함수 부분을 살펴보자.
int main()
{
// array 이를 초기화 한다.
// a 배열과 b 배열 더한 값을 c 배열에 저장할 것이다.
const int arraySize = 5;
const int a[arraySize] = {1, 2, 3, 4, 5};
const int b[arraySize] = {10, 20, 30, 40, 50};
int c[arraySize] = { 0 };
// 벡터 더하는 작업수행
// cudaError_t 는 다양한 error 값을 정의해놓고 있다.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
// 에러가 났는지 확인한다.
if(cudaStatus != cudaSuccess)
{
fprintf(stderr,"addWithCuda failed!");
return 1;
}
}cudaError_t 의 정의를 봐보자.
// enum cudaError 가 cudaError_t 의 다른 이름이다.
typedef __device_builtin__ enum cudaError cudaError_t;
...
// enum cudaError 의 정의는 아래와 같다.
enum __device_builtin__ cudaError
{
cudaSuccess = 0,
cudaErrorMissingConfiguration = 1,
cudaErrorMemoryAllocation = 2,
...
}그럼 위의 예에서 cudaError 값을 프린트 해보자.
int main()
{
...
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
fprintf(stderr, "cudaError : %d\n", cudaStatus);
}이러면 cudatError : 0 이라고 출력되는 것을 볼 수 있다. 0 은 cudaSuccess 를 의미한다.
이어서 코드를 보자.
int main()
{
...
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
fprintf(stderr, "cudaError : %d\n", cudaStatus);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
// 작업 후 결과값을 프린트
printf("{1,2,3,4,5} + {10,20,30,40,50} = %d,%d,%d,%d,%d \n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
// 병렬처리 작업을 수행하고 cudaDeviceReset 을 콜해야한다.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}메인 작업 함수를 분석하자.
cudaError_t addWithCuda(int* c, const int* a, const int* b, unsigned int size)
{
// 메모리 공간을 gpu에 만들어야 한다.
// 먼저 포인터를 선언한다.
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
// 리턴 값에 사용되는 cudaError 타입 변수를 만든다.
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
// GPU 가 여러 개일 경우 1 번 GPU를 사용하기로 설정함.
// GPU 가 1 개일 경우 콜 하지 않아도 기본으로 1번이 잡힘.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output).
// cudaMalloc 은 GPU 메모리에 size 만큼 공간을 할당하는 기능을 한다.
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
// cpu 메모리에 존재하는 값을 gpu 메모리에 복사한다.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
// addKernel은 실제 연산을 코어에서 동작시키는 기능을 한다.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
// 커널 함수가 제대로 동작했는지 확인한다.
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
// 각 코어들이 모두 일을 끝마칠때까지 기다려주는 함수( 이 함수가 없으면 kernel 함수 여러 개일 때 의문사 발생)
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
// 계산 결과를 cpu 메모리에 복사한다.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
// 실행중간 Error 발생 시, GPU 에 할당한 메모리를 반환한다.
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}정리하면 이와 같다.
- GPU 에 메모리를 할당한다.
- CPU 값을 GPU 메모리에 복사한다.
- 코어 작업을 실행한다.
- 결과값을 CPU 메모리로 복사한다.
- GPU에 할당한 메모리를 반환한다.
이제 addKernel 함수는 어떻게 생겼는지 알아보자.
__global__ void addKernel(int* c, const int* a, const int* b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}위 함수에서 threadIdx.x 는 각 thread의 index 정보이다. thread index는 배열 index 마다 할당 되어있다. 따라서 반복문 필요없이 한번에 계산할 수 있다.
CUDA에서 자주 등장하는 개념인 thread, block, grid 에 대한 개념과 커널 함수에 붙어있는 global 을 포함한 지시어는 다음 글에서 다루도록 하겠다.