ImageProcessing 에 사용된 기술(Adaptive Binarization)을 GPU로 처리해보자
이번 포스팅에서 기존 영상처리에 사용되었던 기술인 Adaptive Binarization 을 CUDA 를 이용해 구현하는 방법을 알아볼 것이다.
그전에 extern “C” 선언에 대해서 알아보자. 보통 extern 선언은 외부 소스파일의 전역변수나 함수를 참조할 때 쓰는 선언이다. 함수의 경우 extern 선언을 하지 않고 쓸 수도 있다.
하지만 exter “C” 선언의 경우 의미가 약간 다르다.
extern “C” 란?
링커는 작업시 오브젝트간 함수 이용 및 위치를 알고 있어야 한다. 함수에 관한 이러한 정보는 컴파일러가 오브젝트 파일에 기록한다. 이러한 정보를 linkage라고 한다.
linkage 작업을 하면 함수이름 앞 또는 뒤에 ‘_’ 등의 심볼을 덧붙이게 된다. 그런데 C 와 C++ 은 컴파일 linkage 작업시 변수명, 함수명 등에 심볼을 기록하는 방식이 다르다.
왜냐하면 C 는 overloading 을 지원하지 않아 함수 이름이 유일한 반면, C++ 은 지원하기 때문에 인자의 개수와 데이터 타입에 대한 정보까지 넣어야 하기 때문이다. 그러므로 C 와 C++ 을 혼용하는 프로그램에서는 extern “C” 선언을 하여 각각의 방식으로 linkage 하도록 지시해야 한다.
extern “C” 선언은 C++ 방식이 아닌 C 방식으로 linkage 하도록 지시하는 역할을 한다.
CUDA 를 위한 환경설정
CUDA 소스 코드를 CUDA 컴파일러가 컴파일 할 수 있도록 Visual Studio 환경설정을 해보자.
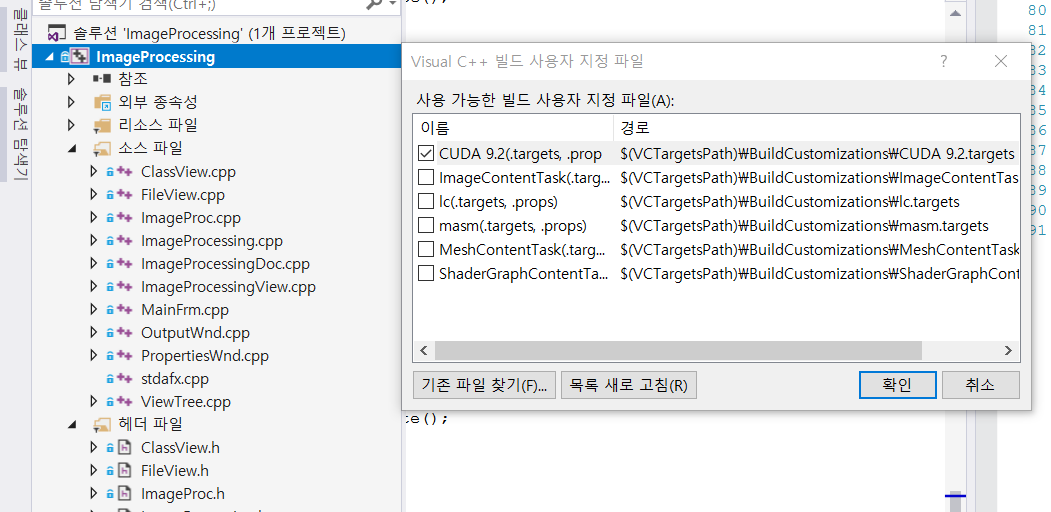
- 프로젝트에서 마우스 오른쪽 클릭 후 빌드 종속성, 사용자 지정 빌드를 클릭 후 아래 그림처럼 CUDA 에 체크한다.
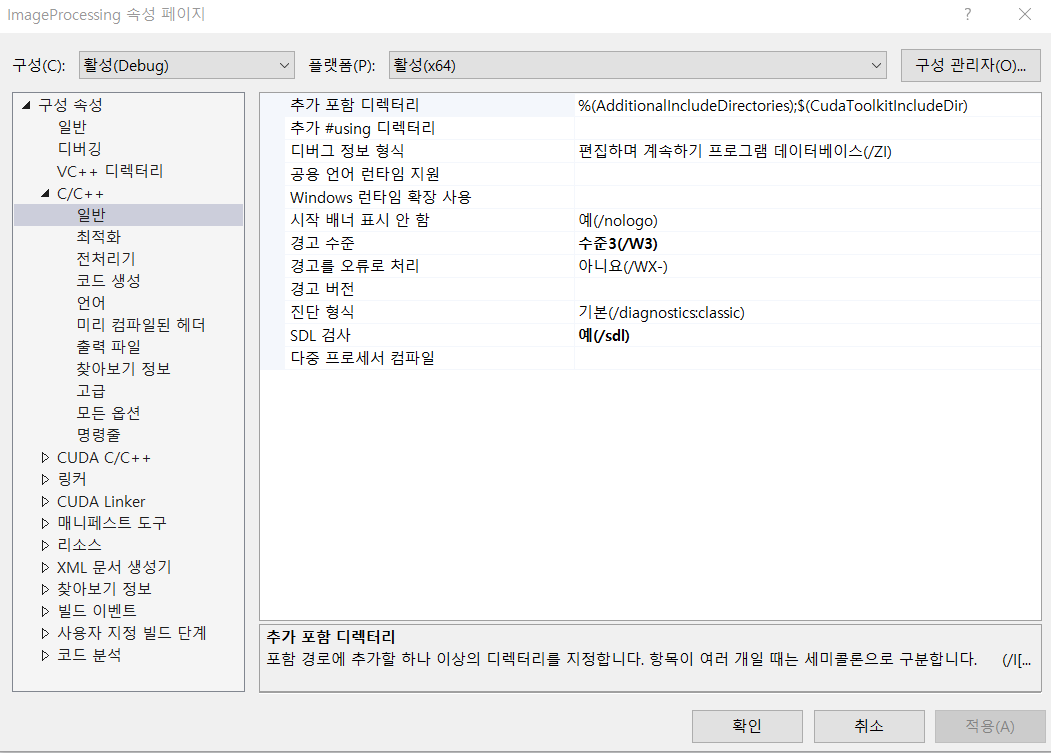
- 메뉴 - 프로젝트 - 프로젝트 속성 - C/C++ - 일반 - 추가 포함 디렉터리
이 곳에 $(CUDA_PATH)/include 를 추가한다. 추가하지 않아도 자동입력 되어있을 수 있다.
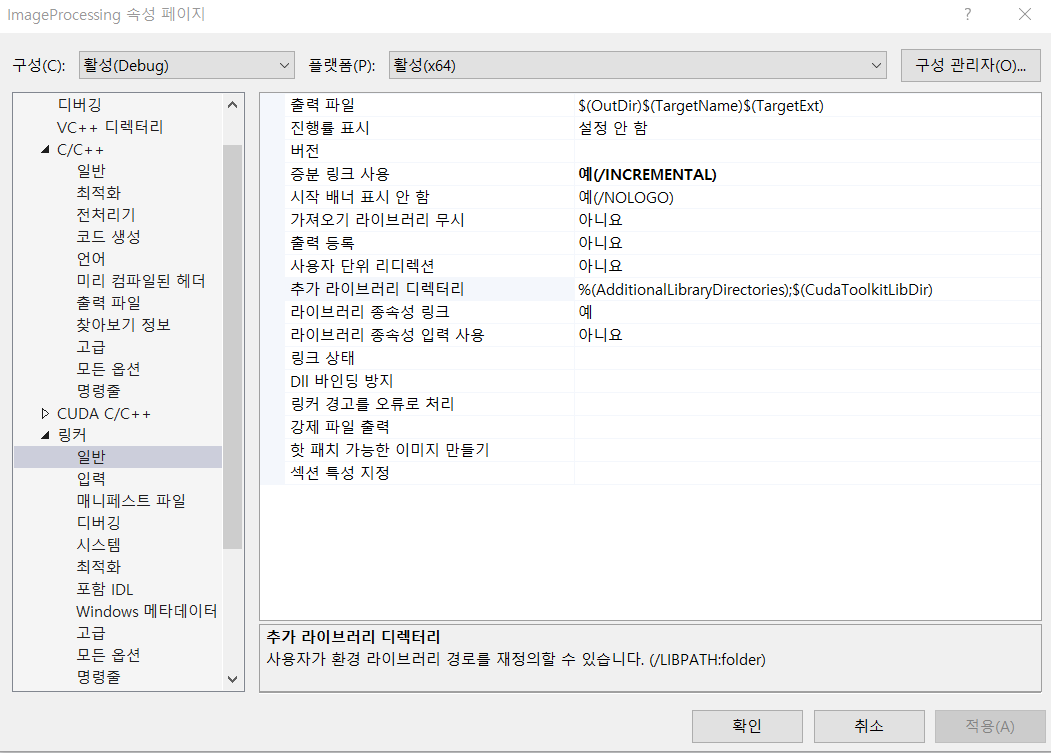
- 링커 - 일반 - 추가 라이브러리 디렉터리
여기에 $(CUDA_PATH)/Win32 를 추가한다. CUDA에 사용되는 라이브러리 폴더 경로를 설정하는 작업이다.
- 링커 - 입력 - 추가 종속성
추가적으로 사용할 라이브러리를 입력한다. cudart_static.lib 를 입력한다.
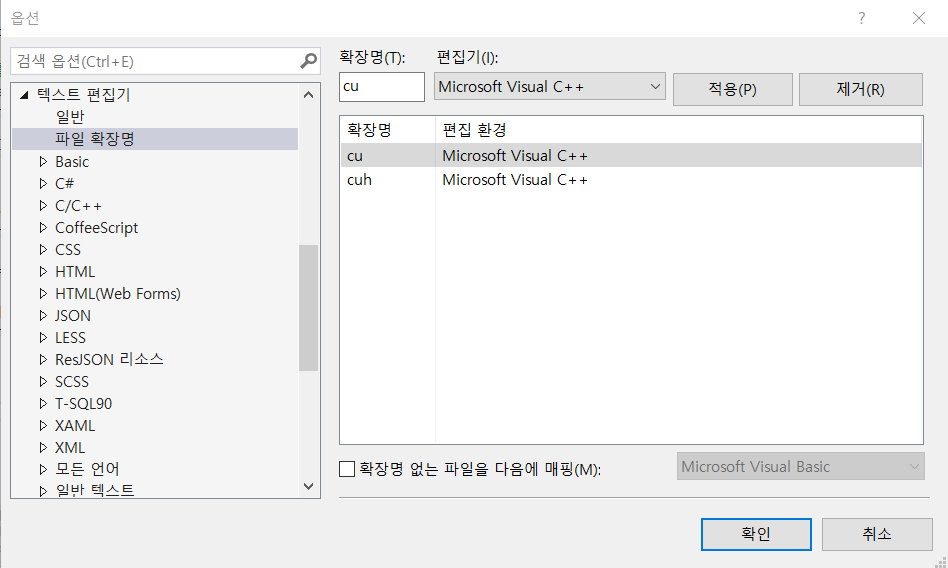
- 도구 - 옵션 - 텍스트 편집기 - 파일 확장명
여기에 cu 와 cuh 확장명을 등록하고 Microsoft Visual C++ 을 편집환경으로 만든다.
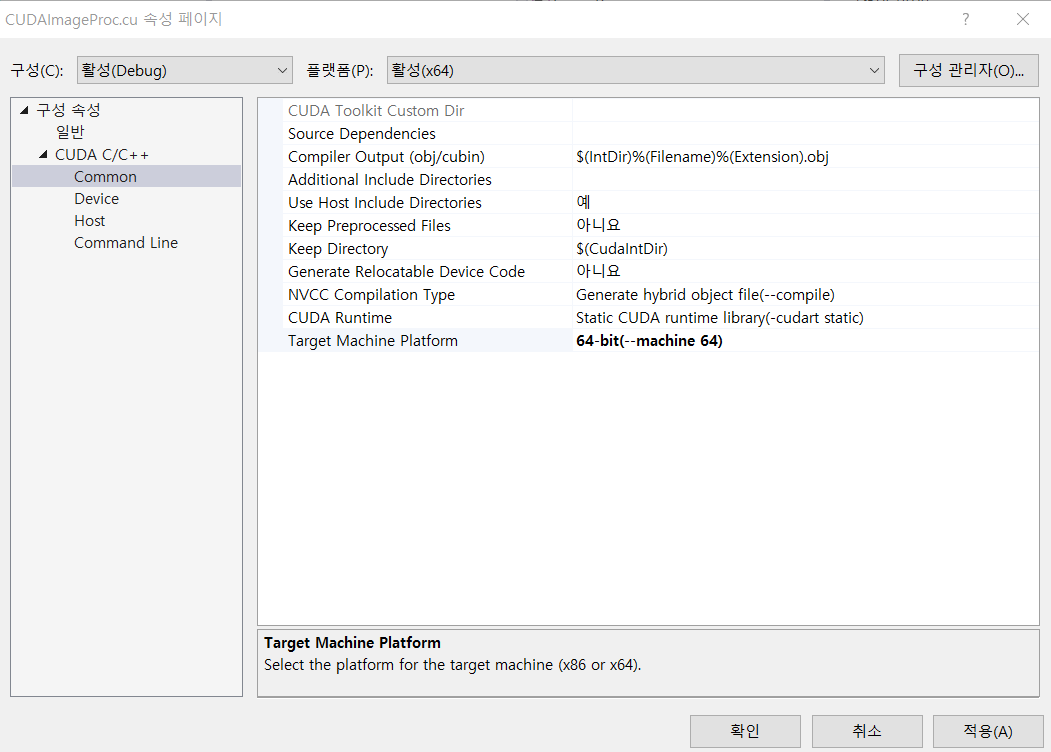
- .cu 확장자로 소스파일 만들고 속성 - 구성속성 - 일반, 속성 - 구성속성 - CUDA C/C++ - common 을 다음과 같이 세팅한다.
개발 시작 // 먼저 큰 그림, 구조는 무엇일지 생각해보자.
- CUDAImageProc.cu 파일에서 정의한 함수는 ImageProc.cpp 에서 콜한다.
- ImageProc.cpp 에 CUDA 함수를 콜하는 헬퍼 함수를 정의한다.
- CUDAImageProc.cu 파일에서 kernel 함수를 정의하고 kernel 함수 콜을 돕는 헬퍼함수도 정의한다.
- CUDA 관련 기능은 모두 CUDAImageProc.cu에 정의한다.
- ImageProcessingDoc.cpp 에 이벤트처리기를 만들고 ImageProc.cpp 의 함수를 콜한다.
CUDAImageProc.cu 에 GPU 메모리 할당 할 변수를 선언하고 GPU 메모리를 세팅하는 기능을 만들어보자
CUDAImageProc.cu
# include "cuda_runtime.h"
# include "device_launch_parameter.h"
# include <stdio.h>
// gpu에 할당할 메모리를 저장할 변수를 선언한다.
// 하나는 호스트에서 받아올 용도 다른 하나는 호스트로 넘겨줄 용도
unsigned char* g_tempBuffer[2] = { nullptr };
// gpu에 할당된 메모리를 0으로 세팅하는 함수를 정의한다.
// 영상처리 할 것이므로 width와 height를 인자로 받는다.
int ImageProc_InitializeMemory(int width, int height)
{
cudaError cudaStatus;
cudaStatus = cudaMemset(g_tempBuffer[0], 0,
sizeof(unsigned char)*width*height);
// 첫번째 메모리 세팅에 실패하면 -1을 반환한다.
if (cudaStatus != cudaSuccess)
return -1;
cudaStatus = cudaMemset(g_tempBuffer[1], 0,
sizeof(unsigned char)*width*height);
// 두번째 메모리 세팅에 실패하면 -2을 반환한다.
if (cudaStatus != cudaSuccess)
return -2;
return 1;
}
// gpu에 메모리를 할당하는 함수를 정의한다.
// 해당 기능은 외부에서 쓰이므로 extern "C" 선언을 해준다.
extern "C"
int ImageProc_AllocGPUMemory(int width, int height)
{
cudaError cudaStatus;
cudaStatus = cudaMalloc((void**)&g_tempBuffer[0],
sizeof(unsigned char)*width*height);
// 첫번째 메모리 할당에 실패하면 -1을 반환한다.
if (cudaStatus != cudaSuccess)
return -1;
cudaStatus = cudaMalloc((void**)&g_tempBuffer[1],
sizeof(unsigned char)*width*height);
// 두번째 메모리 할당에 실패하면 -2을 반환한다.
if (cudaStatus != cudaSuccess)
return -2;
// 할당한 메모리를 0 으로 세팅한다.
return ImageProc_InitializeMemory(width, height);
}
// gpu에 할당한 메모리를 반환하는 기능을 정의한다.
int ImageProc_DeAllocGPUMemory(void)
{
cudaError cudaStatus;
cudaStatus = cudaFree(g_tempBuffer[0]);
// 첫번째 메모리 반환에 실패하면 -1을 반환한다.
if (cudaStatus != cudaSuccess)
return -1;
cudaStatus = cudaFree(g_tempBuffer[1]);
// 두번째 메모리 반환에 실패하면 -2을 반환한다.
if (cudaStatus != cudaSuccess)
return -2;
return 1;
}ImageProc에 메모리를 할당하고 반환하는 작업을 도와줄 함수를 만들어보자.
ImageProc.h
...
//CUDAImageProc.cu 에 정의한 함수를 쓰기위해 선언한다.
extern "C"
{
int ImageProc_AllocGPUMemory(int width, int height);
int ImageProc_DeAllocGPUMemory();
}
class ImageProc
{
...
public:
bool AllocateGPUMemory(int width, int height);
bool DeAllocateGPUMemory(void);
}기존과는 다르게 이번에 정의한 함수는 static 선언이 붙지 않았다. 즉, 객체를 생성해야 사용할 수 있다.
ImageProc.cpp
bool ImageProc::AllocateGPUMemory(int width, int height)
{
if (ImageProc_AllocGPUMemory(width, height))
return true;
else
return false;
}
bool ImageProc::DeAllocateGPUMemory(void)
{
if (ImageProc_DeAllocGPUMemory())
return true;
else
return false;
}이제 Adaptive Binarization 수행하는 기능을 만들어보자.
CUDAImageProc.cu
extern "C"
int ImageProc_AdaptiveBinarization(unsigned char* image_gray,
int width, int height, int ksize)
{
// GPU에 메모리 할당하고 0으로 세팅한다.
if (ImageProc_AllocGPUMemory(width, height) < 0)
return -1;
// GPU 메모리에 호스트 데이터 복사한다.
cudaError cudaStatus;
cudaStatus = cudaMemcpy(g_tempBuffer[0],image_gray,
sizeof(unsigned char)*width*height, cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
return -2;
// 커널 함수를 실행한다.
// GridDim.x, GridDim.y, BlockDim.x, BlockDim.y 를 정의한다.
dim3 Db = dim3(8,8);
dim3 Dg = dim3((width + Db.x - 1) / Db.x, (height + Db.y - 1) / Db.y);
Kernel_AdaptiveBinarization<<< Dg, Db >>> (g_tempBuffer[0],
g_tempBuffer[1],width,height,ksize);
// 커널 함수 실행이 제대로 되었는지 확인한다.
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess)
return -3;
// 커널 함수 모두 종료를 확인한다.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess)
return -4;
// 결과를 호스트 메모리로 복사한다.
cudaStatus = cudaMemcpy(image_gray, g_tempBuffer[1],
sizeof(unsigned char)*width*height, cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
return -5;
return 1;
}커널함수를 정의한다. 블락 index와 thread index 를 이용해 절대 thread index를 알아내는 것이 관건이다.
CUDAImageProc.cu
__global__ void Kernel_AdaptiveBinarization(unsigned char* image_gray,
unsigned char* output_image, int width, int height, int ksize)
{
if (ksize == 1 || ksize % 2 == 0) return;
int neighbor = ksize / 2;
// blockIdx, blockDim, threadIdx 로 좌표를 찾는다.
// blockDim 은 block 사이즈 이므로 아래와 같이 좌표를 구할 수 있다.
int i = blockIdx.x*blockDim.x+threadIdx.x;
int j = blockIdx.y*blockDim.y+threadIdx.y;
float avg = 0.f;
float cnt = 0.f;
for (int x = -neighbor; x <= neighbor; x++)
{
for (int y = -neighbor; y <= neighbor; y++)
{
if (i + x < 0 || i + x >= width || j + y < 0 || j + y >= height)
continue;
avg += image_gray[width*(j + y) + (i + x)];
cnt += 1.f;
}
}
avg = avg / cnt;
if (image_gray[width*j + i] > avg)
output_image[width*j + i] = 255;
else
output_image[width*j + i] = 0;
}ImageProc.cpp 에 위 기능을 사용할 수 있는 함수를 정의하자
ImageProc.h
extern "C"
{
...
int ImageProc_AdaptiveBinarization(image_gray,width,height,ksize);
}
...
// ImageProc 에서 정의할 함수도 선언한다. .. 생략.ImageProc.cpp
bool ImageProc::GPU_AdaptiveBinarization(unsigned char* image_gray,
int width, int height, int ksize)
{
printf("GPU_AdaptiveBinarization\n");
int res = ImageProc_AdaptiveBinarization(image_gray, width, height, ksize);
if (res < 0)
{
printf("GPU_AdaptiveBinarization failed error code is %d \n,",res);
return false;
}
else
return true;
}이벤트 처리기를 단다. 기존과 다르게 사용할 ImageProc 함수가 static 이 아니기 때문에 ImageProc 객체를 만들어서 사용한다.
ImageProcessingDoc.h
class CImageProcessingDoc: public CDocument
{
public:
// ImageProc 객체를 참조하는 변수를 선언
ImageProc* obj_ImageProc;
}Doc 클래스가 생성될 때 초기화하고, 소멸할 때 반환하며 새로운 Document가 생성될 때 기존 객체를 삭제하고 새로운 객체를 생성한다.
ImageProcessingDoc.cpp
CImageProcessingDoc::CImageProcessingDoc()
{
// TODO: 여기에 일회성 생성 코드를 추가합니다.
...
obj_ImageProc = nullptr;
}
CImageProcessingDoc::~CImageProcessingDoc()
{
...
if (obj_ImageProc)
delete obj_ImageProc;
}
BOOL CImageProcessingDoc::OnNewDocument()
{
if (!CDocument::OnNewDocument())
return FALSE;
if (obj_ImageProc)
delete obj_ImageProc;
obj_ImageProc = new ImageProc;
return TRUE;
}이벤트 처리기를 달고 시간을 측정해보자
ImageProcessingDoc.cpp
void CImageProcessingDoc::OnImageprocessinggpuAdaptivebinarization()
{
// TODO: 여기에 명령 처리기 코드를 추가합니다.
printf("OnImageprocessing GPU Adaptivebinarization\n");
QueryPerformanceFrequency(&Frequency);
QueryPerformanceCounter(&BeginTime);
obj_ImageProc->GPU_AdaptiveBinarization(m_Images[cur_index].image_gray,
m_Images[cur_index].width, m_Images[cur_index].height, 87);
QueryPerformanceCounter(&Endtime);
int elapsed = Endtime.QuadPart - BeginTime.QuadPart;
double duringtime = (double)elapsed / (double)Frequency.QuadPart;
printf("GPU AdaptiveBinarization time : %f\n", duringtime);
// GPU Memory DeAllocation
obj_ImageProc->DeAllocateGPUMemory();
CImageProcessingView* pView = (CImageProcessingView*)((CMainFrame*)(AfxGetApp()->m_pMainWnd))->GetActiveView();
pView->SetDrawImage(m_Images[cur_index].image_color, m_Images[cur_index].image_gray,
m_Images[cur_index].width, m_Images[cur_index].height, 1);
pView->OnInitialUpdate();
}실행하면 다음 그림과 같이 되고

시간은 CUDA 프로그래밍 적용 했을 때 : 2.74454초
CUDA 프로그래밍 적용 하지 않았을 때 : 7.01979초
로 CUDA 프로그래밍이 더 빠른 것을 확인 할 수 있다.